Research
AI Security
Adversarial Robustness

Studies have showed that machine learning models, not only neural networks, are vulnerable to adversarial examples. By adding imperceptible perturbations to the original inputs, the attacker can get adversarial examples to fool a learned classifier. Adversarial examples are indistinguishable from the original input image to human, but are misclassified by the classifier. To illustrate, consider the above bagel images. To humans, the two images appear to be the same -- the vision system of human will identify each image as a bagel. The image on the left side is an ordinary image of a bagel (the original image). However, the image on the right side is generated by adding a small and imperceptible perturbation that forces a particular classifier to classify it as a piano. Adversarial attacks are not limited to image classification models; they can also fool other types of machine learning models. Given the widespread application of machine learning models in various tasks, it is crucial to study the security issues posed by adversarial attacks.
Preprints and Publications of this direction:
TART: Boosting Clean Accuracy Through Tangent Direction Guided Adversarial Training. Bongsoo Yi, Rongjie Lai, and Yao Li. Under Review, 2024.
Uncovering Distortion Differences: A Study of Adversarial Attacks and Machine Discriminability. Xiawei Wang, Yao Li, Cho-Jui Hsieh, and Thomas C. M. Lee. In IEEE Access, 2024.
Adversarial Examples Detection With Bayesian Neural Network. Yao Li, Tongyi Tang, Cho-Jui Hsieh, Thomas C. M. Lee. In IEEE TETCI, 2024.
ADDMU: Detection of Far-Boundary Adversarial Examples with Data and Model Uncertainty Estimation. Fan Yin, Yao Li, Cho-Jui Hsieh, Kai-Wei Chang. In EMNLP, 2022.
A Review of Adversarial Attack and Defense for Classification Methods. Yao Li, Minhao Cheng, Cho-Jui Hsieh, Thomas C. M. Lee. In The American Statistician, 2021.
Towards Robustness of Deep Neural Networks via Regularization. Yao Li, Martin Renqiang Min, Thomas C. M. Lee, Wenchao Yu, Erik Kruus, Wei Wang, Cho-Jui Hsieh. In ICCV, 2021.
Adv-BNN: Improved Adversarial Defense through Robust Bayesian Neural Network. Xuanqing Liu, Yao Li, Chongruo Wu, Cho-Jui Hsieh. In ICLR, 2019.
Backdoor Learning
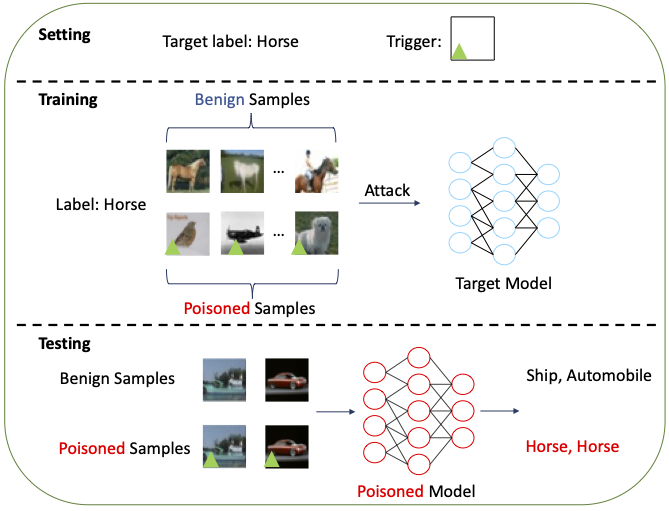
Artificial Intelligence (AI) has become one of the most exciting areas in recent years, as it has achieved state-of-the-art performance and demonstrated fundamental breakthroughs in many challenging tasks. The Achilles’ heel of the technology, however, is what makes it possible -- learning from data. By poisoning the training data, adversaries can corrupt the model, causing severe or even drastic consequences. Backdoor attacks insert a hidden backdoor into a target model so that the model performs well on benign examples, but when a specific pattern, often known as a trigger, appears in the input data, the model will produce incorrect results, such as associating the trigger with a target label irrespective of what the true label is. For example, the figure above gives a specific example of a backdoor attack on image data, but our research is not limited to studying this type of backdoor attack.
Preprints and Publications of this direction:
Defense Against Syntactic Textual Backdoor Attacks with Token Substitution. Xianwen He, Xinglin Li, Yao Li, and Minhao Cheng. In IEEE TIFS, 2025.
Trusted Aggregation (TAG): Backdoor Defense in Federated Learning. Joseph Daniel Lavond, Minhao Cheng, and Yao Li. In TMLR, 2024.
Other Works Related to AI Security
Preprints and Publications of this direction:
Improving Logits-based Detector without Logits from Black-box LLMs. Cong Zeng, Shengkun Tang, Xianjun Yang, Yuanzhou Chen, Yiyou Sun, Zhiqiang Xu, Yao Li, Haifeng Chen, Wei Cheng, and Dongkuan Xu. In NeurIPS, 2024.
Computational Pathology
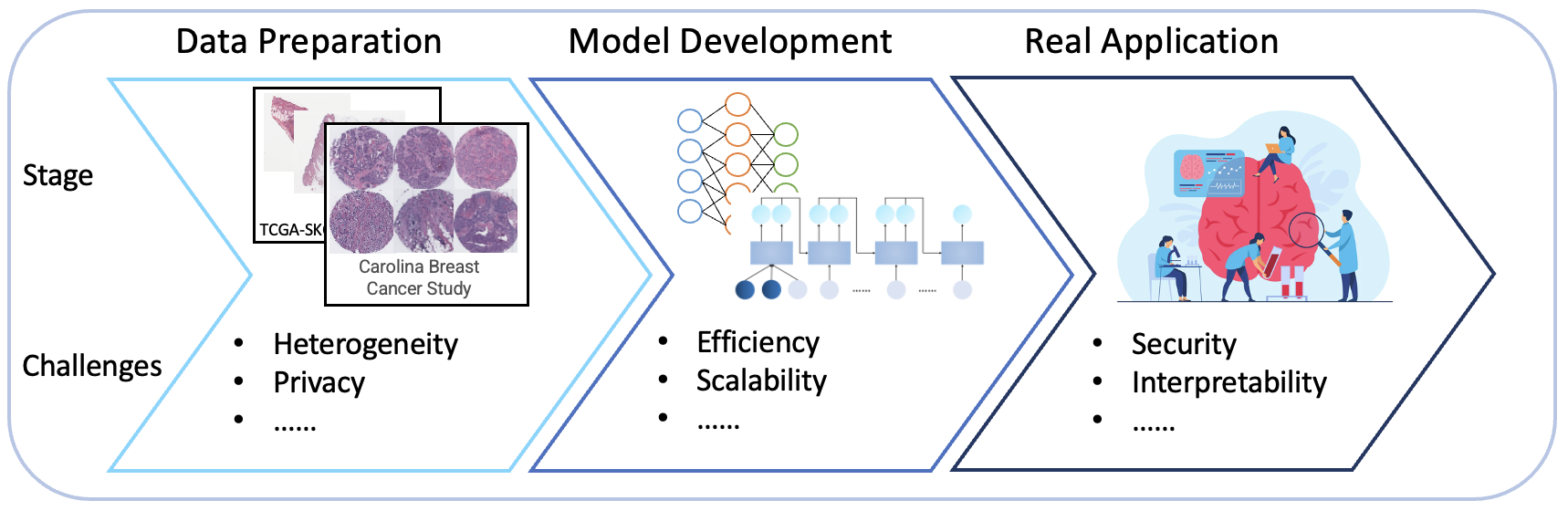
Despite extensive research in applying machine learning methods to medical image analysis, many challenges in this field remain unsolved. The figure above illustrates the pipeline for developing a machine learning system for medical image analysis, highlighting the challenges at each stage. Our focus is on addressing the problems that arise at each step of this pipeline to enhance the utilization of medical images
Preprints and Publications of this direction:
Stain SAN: Simultaneous Augmentation and Normalization for Histopathology Images. Taebin Kim, Yao Li, Benjamin C. Calhoun, Aatish Thennavan, Lisa A. Carey, W. Fraser Symmans, Melissa A. Troester, Charles M. Perou, and J.S. Marron. In JMI, 2024.
Image Analysis-based Identification of High Risk ER-Positive, HER2-Negative Breast Cancers. Dong Neuck Lee, Yao Li, Linnea T. Olsson, Alina M. Hamilton, Benjamin C. Calhoun, Katherine A. Hoaddley, J.S. Marron, Melissa A. Troester. In Breast Cancer Research, 2024.
Region of Interest Detection in Melanocytic Skin Tumor Whole Slide Images - Nevus & Melanoma. Yi Cui, Yao Li, Jayson R. Miedema, Sharon N. Edmiston, Sherif Farag, J. S. Marron, and Nancy E. Thomas. In Cancers, 2024.
Visual Intratumor Heterogeneity and Breast Tumor Progression. Yao Li, Sarah C. Van Alsten, Dong Neuck Lee, Taebin Kim, Benjamin C. Calhoun, Charles M. Perou, Sara E. Wobker, J.S. Marron, Katherine A. Hoadley, and Melissa A. Troester. In Cancers, 2024.
Multiple Instance Learning for Breast Cancer Histopathology Images. Taebin Kim, Benjamin C. Calhoun, Yao Li, Aatish Thennavan, Lisa A. Carey, W. Fraser Symmans, Melissa A. Troester, Charles M. Perou, and J.S. Marron. 2024.
L-Arginine Supplementation in Severe Asthma. Shu-Yi Liao, Megan R Showalter, Angela L Linderholm, Lisa Franzi, Celeste Kivler , Yao Li, Michael R Sa, Zachary A Kons, Oliver Fiehn, Lihong Qi, Amir A Zeki, Nicholas J Kenyon. In JCI Insight, 2020.
AI Efficiency
To apply machine learning to a real-world problem, we design a model (such as a deep neural network) for that problem, train the model using training data, and then deploy the model in the application to interact with the real world. There are many difficulties in this pipeline that restrict the applicability of machine learning. First, designing machine learning models that can work with various types of data efficiently is a challenging task as one method may work well on a certain type of data but may not be applicable to other types due to large scale or some other limitations.Preprints and Publications of this direction:
AdaDiff: Accelerating Diffusion Models through Step-Wise Adaptive Computation. Shengkun Tang, Yaqing Wang, Caiwen Ding, Yi Liang, Yao Li, Dongkuan Xu. In ECCV, 2024.
Feddecay: Adapting to Data Heterogeneity in Federated Learning with Within-round Learning Rate Decay. Joseph Daniel Lavond, Minhao Cheng, and Yao Li. Under Review, 2024.
Biased Dueling Bandits with Stochastic Delayed Feedback. Bongsoo Yi, Yue Kang, and Yao Li. In TMLR 2024.
You Need Multiple Exiting: Dynamic Early Exiting for Accelerating Unified Vision Language Model. Shengkun Tang, Yaqing Wang, Zhenglun Kong, Tianchi Zhang, Yao Li, Caiwen Ding, Yanzhi Wang, Yi Liang, Dongkuan Xu. In CVPR, 2023.
Accelerating Dataset Distillation via Model Augmentation. Lei Zhang, Jie Zhang, Bowen Lei, Subhabrata Mukherjee, Xiang Pan, Bo Zhao, Caiwen Ding, Yao Li, Dongkuan Xu. In CVPR, 2023.
Uncertainty Quantification for High-Dimensional Sparse Nonparametric Additive Models. Qi Gao, Randy C. S. Lai, Thomas C. M. Lee, Yao Li. In Technometrics, 2019.
Learning from Group Comparisons: Exploiting Higher Order Interactions. Yao Li, Minhao Cheng, Kevin Fujii, Fushing Hsieh, Cho-Jui Hsieh. In NeurIPS, 2018.
Scalable Demand-aware Recommendation. Jinfeng Yi, Cho-Jui Hsieh, Kush R. Varshney, Lijun Zhang, Yao Li. In NeurIPS, 2017.